Abstract
The preparation of protein libraries is a key issue in protein engineering and biotechnology. Such libraries can be prepared by a variety of methods, starting from the respective gene library. The challenge in gene library preparation is to achieve controlled total or partial randomization at any predefined number and position of codons of a given gene, in order to obtain a library with a maximum number of potentially successful candidates. This purpose is best achieved by the usage of trinucleotide synthons for codon-based gene synthesis. We here review the strategies for the preparation of fully protected trinucleotides, emphasizing more recent developments for their synthesis on solid phase and on soluble polymers, and their use as synthons in standard DNA synthesis.

Graphical Abstract
Introduction
Protein engineering is a highly actual research area with a number of potential applications [1-4]. The construction, adaptation and optimization of proteins can proceed by two major strategies: (i) rational design or (ii) directed evolution. The rational design is based on the introduction of point mutations, insertions or deletions at a defined position of the protein sequence, and requires detailed knowledge of the protein structure and the mechanism of action. On the opposite, directed evolution relies on the selection of a mutant with predefined properties from a random protein library. This strategy is advantageous over the rational design; whenever molecular properties of proteins are investigated that are not yet sufficiently understood, if properties like solvent or temperature stability need to be optimized, or regio-, chemo- or enantioselectivity and substrate specificity shall be changed. Thus, the optimization and variation of proteins, in particular of enzymes, by random mutagenesis and subsequent selection and identification of mutants with improved properties is a favoured method in the field of white biotechnology and biocatalysis, to improve the fitness of enzymes for industrial application [5].
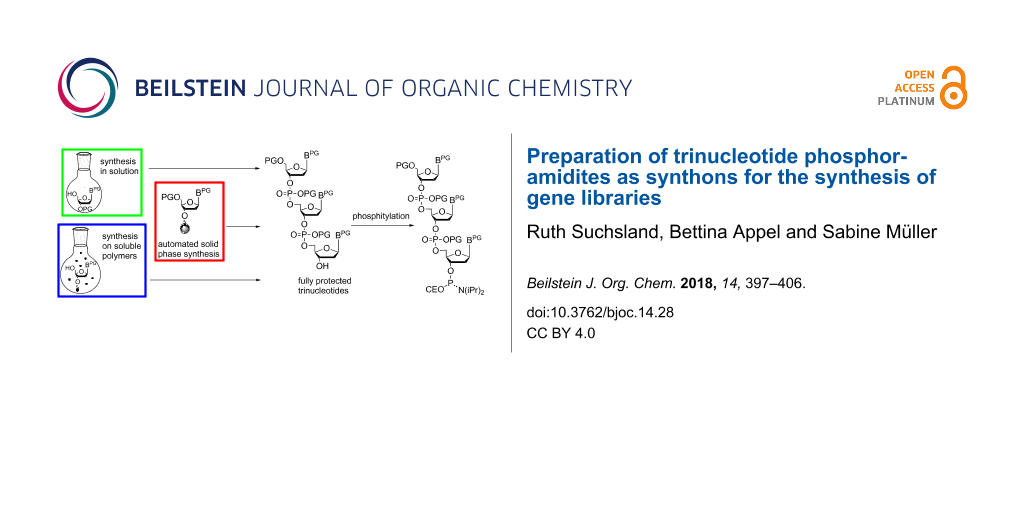
In general, directed evolution may be summarized as an iterative two-step process which involves the generation of protein mutant libraries and high throughput screening processes to select for variants with improved traits. Protein mutant libraries are produced from gene libraries, which are generated by random mutagenesis at DNA level. Often polymerase chain raction (PCR)-based methods like error-prone PCR are used for this purpose as well as recombinant methods like DNA shuffling and related strategies [6,7]. One of the major challenges in gene library production is to generate libraries with a high number of promising candidates to enhance the chance of selecting functional protein variants. The methods mentioned above allow the degree and localization of randomization to be adjusted to a certain degree, however, full control over mutagenesis is still rather limited. Oligonucleotide-based methods with a number of sophisticated techniques [8] are advantageous here, as they offer a better possibility to control randomization. The basic principle consists of using chemically synthesized primers of mixed composition for introducing subsets of the 20 canonical amino acids at a defined position of the protein [9]. In the simplest way, a mixture of the four standard nucleotides is used for coupling at each randomized position of the primer in DNA synthesis. For a primer with 9 randomized positions (corresponding to three randomized amino acids in the resulting protein) this would lead to 49 = 262144 sequence variants including stop codons and codons of undesired amino acids, and a bias towards amino acids encoded by multiple codons. Moreover, it is impossible to restrict randomization to a defined subset of amino acids at a desired position. Thus, the result is a rather large library, however, with only a small number of potentially successful candidates. There are strategies to at least partially circumvent this problem, like using NNS instead of NNN codons (with N = A, C, G, T; S = C, G) taking advantage of redundancy of the third nucleotide positions in the majority of codons [10], or using spiked oligonucleotides [11], which are synthesized from solutions of the four nucleotide building blocks, each of those contaminated with a "spiking mix" consisting of equal aliquots of each of the four building blocks [9,12]. The required volume of the spiking mix to achieve a desired amount of nucleotide replacements at a defined position of the oligonucleotide can be calculated, such that library size and degree of randomization can be restricted [13,14]. Nevertheless, although those methods and sophisticated variations of them [14-17] have improved library design and synthesis, full control over randomization is not possible. This can be achieved only by the usage of trinucleotide synthons for codon-based synthesis of a desired primer [18]. Taking the example from above, for a DNA fragment encoding three randomized amino acids, instead of nine nucleotide positions to be randomized, variation of trinucleotides (codons for the 20 amino acids) at only three positions is required. Therefore, the number of possible sequence variants in the gene library decreases from 49 = 262144 to 203 = 8000, if the full set of the 20 amino acids is desired at each of the three randomized positions. The library size can be even further decreased by using subsets of amino acids (e.g., only basic or only acidic amino acids) at the individual positions. Furthermore, stop codons as well as bias to amino acids with codon redundancy are completely prevented. Not at last, the coupling efficiency of individual trinucleotide synthons in chemical DNA synthesis can be considered when preparing the trinucleotide mixture, to ensure that each of the trinucleotides is coupled with identical statistical probability, or alternatively, to adjust the trinucleotide mixture to a desired amino acid distribution at the respective position. Thus, the application of trinucleotide building blocks for the synthesis of gene libraries stands out as facilitating fully controlled total or partial randomization at any predefined number and position of codons of a given gene. Trinucleotide synthons need to be chemically synthesized. Here, the challenge has been to find a suitable set of orthogonal protecting groups that allows the preparation of the trinucleotide, its conversion into a coupling competent building block, and its subsequent use in chemical DNA synthesis. Trinucleotides have been prepared in solution [19], on solid phase [20], and more recently on soluble polymers [21-23] (Figure 1), followed by phosphitylation to be used in standard DNA synthesis.
![[1860-5397-14-28-1]](/bjoc/content/figures/1860-5397-14-28-1.svg?scale=2.0&max-width=1024&background=FFFFFF)
Figure 1: Preparation of fully protected trinucleotides in solution (A), on solid phase (B) and on soluble polymers (C).
Figure 1: Preparation of fully protected trinucleotides in solution (A), on solid phase (B) and on soluble po...
The preparation of mixed oligonucleotides for random mutagenesis including the strategy of using trinucleotide synthons has been reviewed recently [19,24]. Therefore, herein we will concentrate on more recent developments in trinucleotide synthesis.
Review
1. Preparation of trinucleotides in solution
Over the years, a number of methodologies has been published, varying in the protecting group for the phosphate moiety being methyl [25], ethyl [26], cyanoethyl [27] or ortho-chlorophenyl [28,29], and for the 3'-OH-group being phenoxyacetyl [25], dimethoxytrityl (DMTr) [26], tert-butyldimethylsilyl (TBDMS) [27,30], levulinoyl [26], or 2-azidomethylbenzoyl [27] (Figure 2), and applying either phosphotriester chemistry [28,29,31,32] or phosphite triester chemistry [25-27,30] in solution.
![[1860-5397-14-28-2]](/bjoc/content/figures/1860-5397-14-28-2.svg?scale=2.0&max-width=1024&background=FFFFFF)
Figure 2: Strategies for trinucleotide synthesis using different pairs of orthogonal groups for protection of the phosphates and the 3'-OH-function.
Figure 2: Strategies for trinucleotide synthesis using different pairs of orthogonal groups for protection of...
In general, trinucleotides can be assembled through the reaction of two suitably protected monomers to generate a dinucleotide, which then can be extended in either 5'- or 3'-direction (Figure 3).
![[1860-5397-14-28-3]](/bjoc/content/figures/1860-5397-14-28-3.svg?scale=2.0&max-width=1024&background=FFFFFF)
Figure 3: Strategy for the synthesis of nucleotide dimers and extension to the trimer in either 5'- or 3'-direction.
Figure 3: Strategy for the synthesis of nucleotide dimers and extension to the trimer in either 5'- or 3'-dir...
Surprisingly, only one report has made use of this "economy", first coupling a 5'-O-DMTr-protected nucleoside-3'-ortho-chlorophenylphosphotriester to a 3'-O-levulinoyl-protected monomer. Upon selective removal of either the 5'-O-DMTr group or the 3'-O-levulinoyl group, the dimer was extended in 5' or 3' direction [26]. All other reports describe strategies, where the dimers are extended unidirectional, either in 5'-direction [25-27,29,30] or 3'-direction [31,32]. A key issue in all these methodologies is that the 5'- or the 3'-O-protecting group is selectively cleaved, whereas all other protecting groups (at the nucleobases, the phosphorous and the 5'- or alternatively 3'-OH group) remain intact.
Basically, this aim has been achieved, although in particular in earlier reports a number of problems associated with insufficient stability of protecting groups under synthesis conditions, as well as restricted orthogonality have been described, which was mirrored in the sometimes severely limited quality of the trinucleotide synthons and accordingly of the prepared oligonucleotide libraries [14,15,25,26,28,30,31,33]. Among the described procedures the use of tert-butyldimethylsilyl [25] and 2-azidomethylbenzoyl groups [29] for 3'-O-protection stands out as being the most successful in terms of high quality trinucleotides. Both protecting groups, under the applied conditions, can be efficiently cleaved, at the same time leaving all other protecting groups intact. Thus, a full set of all 20 trimers was synthesized by phosphotriester chemistry starting with the condensation of N-acyl-3'-O-(o-chlorophenylphosphate)nucleosides to 3'-O-(2-azidomethylbenzoyl)-protected nucelosides, followed by removal of the 5'-O-DMTr group and extension of the dimer to the trimer by coupling of another N-acyl-3'-O-(o-chlorophenylphosphate)nucleoside. The final removal of the 2-azidomethylbenzoyl group occurred by reduction of the azide with triphenylphosphine in aqueous dioxane and subsequent spontaneous intramolecular cyclization leading to cleavage of the ester bond and release of the free 3'-OH group [29] (Figure 4A).
![[1860-5397-14-28-4]](/bjoc/content/figures/1860-5397-14-28-4.svg?scale=2.0&max-width=1024&background=FFFFFF)
Figure 4: Removal of the 3'-O-protecting group under conditions that leave all other protecting groups at 5'-OH, nucleobases and internucleotide phosphates intact.
Figure 4: Removal of the 3'-O-protecting group under conditions that leave all other protecting groups at 5'-...
Also with 3'-O-TBDMS-protected monomers as mentioned above, a full set of trimers representing codons of all 20 amino acids was synthesized, although using phosphite triester chemistry [27]. In this case, the synthesis started with the coupling of an N-acyl-5'-O-DMTr-protected nucleoside-3'-O-phosphoramidite to an N-acyl-3'-O-TBDMS-protected nucleoside, followed by oxidation of the internucleotide phosphorous. Upon cleavage of the 5'-O-DMTr group, the dimer was reacted with another N-acyl-5'-O-DMTr-protected nucleoside-3'-O-phosphoramidite to afford the trimer. The 3'-O-TBDMS group was selectively removed under mild conditions with trimethylamine/3HF (Figure 4B) with strict control of pH to leave the β-cyanoethyl groups at the internucleotide phosphates intact [27]. With both procedures (3'-O-(2-azidomethylbenzoyl) and 3'-O-TBDMS protection), 20 trinucleotides of high purity were prepared and upon phosphitylation used as synthons in oligonucleotide synthesis [27,29].
In general, the reported syntheses of trinucleotides in solution proceed by either phosphite triester chemistry or phosphotriester chemistry with the latter being the more robust method. Also H-phosphonate chemistry has been used for assembling short oligomers in solution [34], although not with the aim of generating trinucleotide synthons for gene synthesis.
2. Preparation of trinucleotides on solid phase
Given the fact that trinucleotide synthesis in solution requires tedious purification and isolation of the products after each step of the synthesis, the assembly of trimers on a solid phase appears to be an attractive alternative. However, it has to be taken into account that the 3'-start nucleoside is required to be linked to the solid phase in a way that allows the cleavage of the trimer from the solid support, but leaves all other protecting groups intact. Therefore, the routinely used succinate linkage for immobilization of the start nucleotide cannot be used. Instead, linkers that allow a release of the trimers by a non-nucleophilic and/or non-basic treatment are required. In terms of trimer synthesis only one report in the literature describes such a strategy: The start nucleoside was loaded onto controlled pore glass (CPG) via an oxalyl anchor (Figure 5A), which after the synthesis was cleaved with a 5% solution of 25% aqueous ammonia in methanol, or with 20% pyridine in methanol [20].
![[1860-5397-14-28-5]](/bjoc/content/figures/1860-5397-14-28-5.svg?scale=2.0&max-width=1024&background=FFFFFF)
Figure 5: Release of trinucleotide blocks from the solid support by cleavage of an oxalyl anchor (A) and by a transesterification mechanism (B).
Figure 5: Release of trinucleotide blocks from the solid support by cleavage of an oxalyl anchor (A) and by a...
Combined with phosphotriester chemistry for trimer assembly, this treatment did not cause damage of the phosphotriester linkages and the nucleobase N-acyl groups. Using this strategy the large scale synthesis (5 g) of 3'-unprotected trinucleotides proceeded with a total 75–90% yield [20].
Other strategies with potential for the solid-phase synthesis of protected trinucleotides might rely on a universal solid support, from which oligomers with free 3'-OH function are released by a transesterification mechanism [35]. The 3'-start nucleoside is bound to one of the primary hydroxy groups of CPG-linked glycerol via an H-phosphonate linkage (Figure 5B). The removal of the TBDMS group from the remaining primary alcohol of glycerol induces the spontaneous cleavage of the H-phosphonate and the release of the oligomer with the free 3'-OH group leaving all other protecting groups intact. This strategy has been shown to be compatible with phosphoramidite chemistry and β-cyanoethyl protection of the internucleotide phosphates [33].
A more recent report describes the preparation of a polystyrene support decorated with a photolabile linker and its potential use for the synthesis of siRNA duplexes under mild and neutral conditions [36]. A similar strategy was used for the synthesis of partially 2'/3'-O-acetylated RNA oligonucleotides [37]. A photo-cleavable linker would also have potential for the synthesis of protected trinucleotides, as it would allow the cleavage of the trimer from the support by irradiation with UV light, without harming nucleobase and internucleotide phosphate protection. Nevertheless, photo-induced formation of byproducts may be an issue to be considered.
In our lab, we have been developing a strategy for solid-phase trinucleotide synthesis involving a disulfide linkage to the support (CPG or polystyrene), which can be cleaved under reductive conditions without harming nucleobase and phosphate protecting groups. The disulfide bridge is generated through the reaction of a 3'-O-methylthiomethyl-functionalized nucleoside with 2-mercaptopropionic acid and subsequent coupling to amino-functionalized CPG or polystyrene. After assembly of the trinucleotide on the support, the disulfide bridge is cleaved by treatment with dithiothreitol (DTT) [38] or tris-(2-carboxyethyl)phosphine (TCEP, Figure 6) leaving all other protecting groups intact.
![[1860-5397-14-28-6]](/bjoc/content/figures/1860-5397-14-28-6.svg?scale=2.0&max-width=1024&background=FFFFFF)
Figure 6: Release of the trinucleotide from the support under reductive conditions.
Figure 6: Release of the trinucleotide from the support under reductive conditions.
The resulting hemi-(S,O)-acetal at the nucleotiode 3'-terminus is spontaneously degraded into the alcohol and thioformaldehyde, thus delivering the trimer with free 3'-OH group for subsequent phosphitylation. The detailed strategy and syntheses will be described elsewhere.
3. Preparation of trinucleotides by inverse solid-phase synthesis
Interestingly, also the use of polymer-supported reagents for H-phosphonate or phosphoramidite activation and phosphite oxidation has been described [34,39], thereby combining the advantages of solution chemistry and solid-phase methods. Thus, solid-supported acyl chloride or pyridinium tosylate as the activator of nucleoside-3'-O-H-phosphonates/phosphoramidites, and polystyrene-bound trimethylammonium periodate as oxidation reagent have been demonstrated to be superior for dimer and trimer synthesis, as complicated purification steps can be avoided, and excess reagents are easily removed by filtration. Compared with standard phosphotriester and phosphite triester chemistry, the limitations of this approach are lower coupling yields and side reactions hampering the yield and quality of the desired products [34,39].
4. Preparation of trinucleotides on soluble supports
Another strategy of combining the advantages of solution chemistry and solid-phase methods is the assembly of oligonucleotides on soluble supports. Among the supports used for this purpose, polyethylene glycol (PEG) has a prominent position, appearing as the routinely used polymer [40-44]. The isolation of intermediate and final products from the reaction mixture proceeds by precipitation from diethyl ether and filtration, thus significantly speeding up the process. In addition, the method is favorable in terms of producing oligonucleotides at a larger scale, since the reaction proceeds in homogeneous solution on a rather cheap polymer. The synthesis of oligonucleotides on soluble supports has been reviewed recently [45], showing that a variety of soluble polymers and precipitative supports are well suited to it. Also the solution-phase synthesis of protected trinucleotide building blocks has been described in the literature [21-23]. In an initial attempt, thymidine as a start nucleoside was tethered to a precipitative tetrapodal soluble support via a disulfide-linker [21] (Table 1, entry 1).
![[Graphic 1]](/bjoc/content/inline/1860-5397-14-28-i1.svg?max-width=637&scale=1.0)
![[Graphic 2]](/bjoc/content/inline/1860-5397-14-28-i2.svg?max-width=637&scale=1.0)
![[Graphic 3]](/bjoc/content/inline/1860-5397-14-28-i3.svg?max-width=637&scale=1.0)
Upon detritylation, the support carrying the start nucleoside now having a free 5'-OH group was precipitated from methanol, followed by coupling with a 5'-O-DMTr-protected nucleoside-3'-O-(o-chlorophenyl)phosphate activated as benzotriazol and renewed precipitation with methanol. The resulting dimer was then extended to the trimer by another cycle of detritylation, precipitation, coupling and precipitation. During reductive cleavage of the disulfide bond to release the fully protected trimer from the support, unfortunately the loss of the 5'-DMTr group was observed. To overcome this hurdle, the disulfide tether was replaced in a following-up study with a Q-linker (hydroquinone-O,O'-diacetic acid), to be cleaved with dilute methanolic K2CO3 for the release of trimers in fully protected form. Five different trimers were assembled at 0.5 mmol scale and released form the support as described [22] (Table 1, entry 2). Thus, the fully protected trinucleotide building blocks were obtained with 65 to 70% yield from three coupling cycles, each containing two precipitations.
Yet another method for the synthesis of oligonucleotide blocks has been developed using a Cbz-type alkyl-chain-soluble support [23]. The support was attached via the benzyloxycarbonyl (Cbz) group to the 3'-OH of the starting nucleoside being adenosine, cytidine, guanosine or thymidine, and trimers were assembled by phosphoramidite chemistry (Table 1, entry 3). The support was found to disperse homogenously in the reaction solvents and to precipitate upon the addition of a polar solvent, typically methanol. After coupling of a standard phosphoramidite building block followed by oxidation with 2-butanone peroxide in dichloromethane, the resulting dimer on the support was again precipitated with methanol and filtered, before detritylation and coupling of the third monomer. The release of the trimer in fully protected form from the support was achieved by hydrogenation with Pd/C (10%) in tetrahydrofurane (THF) for 40 h at room temperature. Three fully protected trimers were prepared this way with isolated yields in the range of 44 to 49% [23].
5. Phosphitylation and coupling of trinucleotide synthons in solid phase DNA synthesis
To be used as building blocks in standard phosphoramidite synthesis, fully protected trimers need to be converted in phosphoramidites (Figure 7).
![[1860-5397-14-28-7]](/bjoc/content/figures/1860-5397-14-28-7.svg?scale=2.0&max-width=1024&background=FFFFFF)
Figure 7: Phosphitylation of trimers. Reaction conditions, in particular the choice of the phosphitylation reagent, are dependent on the nature of the protecting group at the internucleotide phosphates.
Figure 7: Phosphitylation of trimers. Reaction conditions, in particular the choice of the phosphitylation re...
This has been described in a number of reports [19,22,27,29], and is easily achieved with trimers having o-chlorophenyl groups for protection of the phosphate moiety [22,29]. However, phosphitylation becomes a crucial step, if β-cyanoethyl is used as the phosphate protecting group [27]. Using 2-cyanoethyl-N,N-diisopropylchlorophosphoramidite for phosphitylation requires the presence of N,N-diisopropylethylamine (DIPEA) to neutralize HCl that is generated during the reaction. This, however, would lead to the removal of the β-cyanoethyl group at the phosphate moieties, which, due to the phosphorous atom in the oxidized state, is highly sensitive to basic agents and readily undergoes β-elimination [27].
An alternative reagent is 2-cyanoethyl-N,N,N′,N′-tetraisopropylphosphordiamidite in combination with tetrazole derivatives such as benzylmercaptotetrazole. Under those conditions, the phosphitylation proceeds with the production of one equivalent of diisopropylamine, which is neutralized by benzylmercaptotetrazole released back after the reaction. The tetrazole derivative is sufficiently acidic to act as a scavenger for diisopropylamine converting it into the ammonium salt. Thus, fully protected trimers can be converted to phosphoramidites without the loss of the β-cyanoethyl groups at the internucleotide phosphate linkages [27].
For the use in standard oligonucleotide synthesis, trinucleotide phosphoramidites have been dissolved in a mixture of acetonitrile and dichloromethane to a concentration of 0.1–0.15 M. The coupling yields are typically between 70–95%, preferentially with double or triple couplings, and a coupling time of 120 to 300 s [22,27,29].
Conclusion
The synthesis of fully protected trimers can be achieved in solution, on a solid phase or on soluble supports. The key element is the choice of a suitable set of orthogonal protecting groups to allow the selective deprotection of the functionality required for the reaction, while leaving all other protecting groups intact. The first trinucleotide synthesis was performed in solution using phosphotriester or phosphoramidite chemistry. More recently strategies for trimer assembly on a solid phase or soluble supports have been developed. Here, release of the synthesized trimer in fully protected form from the support is the crucial step. This has been convincingly achieved by using molecular entities linking the trimer to the support, which can be selectively cleaved either under reductive conditions (disulfide cleavage or hydrogenation) or under mild basic conditions leaving all protecting groups at the trimer undamaged.
In particular, soluble support strategies have great potential for an efficient large scale synthesis of fully protected trinucleotides. The essential feature here is that small molecular reagents can be easily removed after coupling and 5'-O-deprotection, by quantitative precipitation of the soluble support in a polar solvent, such as methanol.
With the developments in the field of biotechnology and protein engineering, the preparation of gene libraries has become a major issue. In this regard, the use of trinucleotide synthons for codon-based gene synthesis has high potential, as it allows the fully controlled total or partial randomization at any predefined number and position of codons of a given gene. Methods for their large scale preparation are available now.
References
-
Chen, Z.; Zeng, A.-P. Curr. Opin. Biotechnol. 2016, 42, 198–205. doi:10.1016/j.copbio.2016.07.007
Return to citation in text: [1] -
Bornscheuer, U. T.; Huisman, G. W.; Kazlauskas, R. J.; Lutz, S.; Moore, J. C.; Robins, K. Nature 2012, 485, 185–194. doi:10.1038/nature11117
Return to citation in text: [1] -
Truppo, M. D. ACS Med. Chem. Lett. 2017, 8, 476–480. doi:10.1021/acsmedchemlett.7b00114
Return to citation in text: [1] -
Ernst, P.; Plückthun, A. Biol. Chem. 2017, 398, 23–29. doi:10.1515/hsz-2016-0233
Return to citation in text: [1] -
Porter, J. L.; Rusli, R. A.; Ollis, D. L. ChemBioChem 2016, 17, 197–203. doi:10.1002/cbic.201500280
Return to citation in text: [1] -
Packer, M. S.; Liu, D. R. Nat. Rev. Genet. 2015, 16, 379–394. doi:10.1038/nrg3927
Return to citation in text: [1] -
Sullivan, B.; Walton, A. Z.; Stewart, J. D. Enzyme Microb. Technol. 2013, 53, 70–77. doi:10.1016/j.enzmictec.2013.02.012
Return to citation in text: [1] -
Sauer, N. J.; Mozoruk, J.; Miller, R. B.; Warburg, Z. J.; Walker, K. A.; Beetham, P. R.; Schöpke, C. R.; Gocal, G. F. Plant Biotechnol. J. 2016, 14, 496–502. doi:10.1111/pbi.12496
Return to citation in text: [1] -
Derbyshire, K. M.; Salvo, J. J.; Grindley, N. D. Gene 1986, 46, 145–152. doi:10.1016/0378-1119(86)90398-7
Return to citation in text: [1] [2] -
Isalan, M. Nat. Protoc. 2006, 1, 468–475. doi:10.1038/nprot.2006.68
Return to citation in text: [1] -
Stemmer, W. P. Proc. Natl. Acad. Sci. U. S. A. 1994, 91, 10747–10751. doi:10.1073/pnas.91.22.10747
Return to citation in text: [1] -
Cárcamo, E.; Roldán-Salgado, A.; Osuna, J.; Bello-Sanmartin, I.; Yáñez, J. A.; Saab-Rincón, G.; Viadiu, H.; Gaytán, P. ACS Omega 2017, 2, 3183–3191. doi:10.1021/acsomega.7b00508
Return to citation in text: [1] -
Dale, S. J.; Belfield, M.; Richardson, T. C. Methods 1991, 3, 145–153. doi:10.1016/S1046-2023(05)80167-7
Return to citation in text: [1] -
Gaytán, P.; Yáñez, J.; Sánchez, F.; Soberón, X. Nucleic Acids Res. 2001, 29, E9. doi:10.1093/nar/29.3.e9
Return to citation in text: [1] [2] [3] -
Arkin, A. P.; Youvan, D. C. BioTechnology 1992, 10, 297–300. doi:10.1038/nbt0392-297
Return to citation in text: [1] [2] -
Jensen, L. J.; Andersen, K. V.; Svendsen, A.; Kretzschmar, T. Nucleic Acids Res. 1998, 26, 697–702. doi:10.1093/nar/26.3.697
Return to citation in text: [1] -
Tomandl, D.; Schober, A.; Schwienhorst, A. J. Comput.-Aided Mol. Des. 1997, 11, 29–38. doi:10.1023/A:1008071310472
Return to citation in text: [1] -
Popova, B.; Schubert, S.; Bulla, I.; Buchwald, D.; Kramer, W. PLoS One 2015, 10, e0136778. doi:10.1371/journal.pone.0136778
Return to citation in text: [1] -
Arunachalam, T. S.; Wichert, C.; Appel, B.; Müller, S. Org. Biomol. Chem. 2012, 10, 4641–4650. doi:10.1039/c2ob25328c
Return to citation in text: [1] [2] [3] -
Kayushin, A.; Korosteleva, M.; Miroshnikov, A. Nucleosides, Nucleotides Nucleic Acids 2000, 19, 1967–1976. doi:10.1080/15257770008045471
Return to citation in text: [1] [2] [3] -
Jabgunde, A. M.; Molina, A. G.; Virta, P.; Lönnberg, H. Beilstein J. Org. Chem. 2015, 11, 1553–1560. doi:10.3762/bjoc.11.171
Return to citation in text: [1] [2] [3] -
Kungurtsev, V.; Lonnberg, H.; Virta, P. RSC Adv. 2016, 6, 105428–105432. doi:10.1039/C6RA22316H
Return to citation in text: [1] [2] [3] [4] [5] [6] -
Matsuno, Y.; Shoji, T.; Kim, S.; Chiba, K. Org. Lett. 2016, 18, 800–803. doi:10.1021/acs.orglett.6b00077
Return to citation in text: [1] [2] [3] [4] -
Raetz, R.; Appel, B.; Müller, S. Chim. Oggi 2016, 34, 14–17.
Return to citation in text: [1] -
Virnekas, B.; Ge, L.; Plückthun, A.; Schneider, K. C.; Wellnhofer, G.; Moroney, S. E. Nucleic Acids Res. 1994, 22, 5600–5607. doi:10.1093/nar/22.25.5600
Return to citation in text: [1] [2] [3] [4] [5] [6] -
Yáñez, J.; Argüello, M.; Osuna, J.; Soberón, X.; Gaytán, P. Nucleic Acids Res. 2004, 32, e158. doi:10.1093/nar/gnh156
Return to citation in text: [1] [2] [3] [4] [5] [6] [7] -
Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b
Return to citation in text: [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] -
Zehl, A.; Starke, A.; Cech, D.; Hartsch, T.; Merkl, R.; Fritz, H.-J. Chem. Commun. 1996, 2677–2678. doi:10.1039/cc9960002677
Return to citation in text: [1] [2] [3] -
Yagodkin, A.; Azhayev, A.; Roivainen, J.; Antopolsky, M.; Kayushin, A.; Korosteleva, M.; Miroshnikov, A.; Randolph, J.; Mackie, H. Nucleosides, Nucleotides Nucleic Acids 2007, 26, 473–497. doi:10.1080/15257770701426260
Return to citation in text: [1] [2] [3] [4] [5] [6] [7] [8] [9] -
Lyttle, M. H.; Napolitano, E. W.; Calio, B. L.; Kauvar, L. M. BioTechniques 1995, 19, 274–281.
Return to citation in text: [1] [2] [3] [4] -
Ono, A.; Matsuda, A.; Zhao, J.; Santi, D. V. Nucleic Acids Res. 1995, 23, 4677–4682. doi:10.1093/nar/23.22.4677
Return to citation in text: [1] [2] [3] -
Kayushin, A. L.; Korosteleva, M. D.; Miroshnikov, A. I.; Kosch, W.; Zubov, D.; Piel, N. Nucleic Acids Res. 1996, 24, 3748–3755. doi:10.1093/nar/24.19.3748
Return to citation in text: [1] [2] -
Sondek, J.; Shortle, D. Proc. Natl. Acad. Sci. U. S. A. 1992, 89, 3581–3585. doi:10.1073/pnas.89.8.3581
Return to citation in text: [1] [2] -
Adamo, I.; Dueymes, U.; Schönberger, A.; Navarro, A.-E.; Meyer, A.; Lange, M.; Imbach, J.-L.; Link, F.; Morvan, F.; Vasseur, J.-J. Eur. J. Org. Chem. 2006, 436–448. doi:10.1002/ejoc.200500547
Return to citation in text: [1] [2] [3] -
Ferreira, F.; Meyer, A.; Vasseur, J.-J.; Morvan, F. J. Org. Chem. 2005, 70, 9198–9206. doi:10.1021/jo051172n
Return to citation in text: [1] -
Lietard, J.; Hassler, M. R.; Fakhoury, J.; Damha, M. J. Chem. Commun. 2014, 50, 15063–15066. doi:10.1039/C4CC07153K
Return to citation in text: [1] -
Xu, J.; Duffy, C. D.; Chan, C. K. W.; Sutherland, J. D. J. Org. Chem. 2014, 79, 3311–3326. doi:10.1021/jo5002824
Return to citation in text: [1] -
Semenyuk, A.; Földesi, A.; Johansson, T.; Estmer-Nilsson, C.; Blomgren, P.; Brännvall, M.; Kirsebom, L. A.; Kwiatkowski, M. J. Am. Chem. Soc. 2006, 128, 12356–12357. doi:10.1021/ja0636587
Return to citation in text: [1] -
Dueymes, C.; Schönberger, A.; Adamo, I.; Navarro, A.-E.; Meyer, A.; Lange, M.; Imbach, J.-L.; Link, F.; Morvan, F.; Vasseur, J.-J. Org. Lett. 2005, 7, 3485–3488. doi:10.1021/ol0511777
Return to citation in text: [1] [2] -
Bonora, G. M.; Scremin, C. L.; Colonna, F. P.; Garbesi, A. Nucleic Acids Res. 1990, 18, 3155–3159. doi:10.1093/nar/18.11.3155
Return to citation in text: [1] -
Bonora, G. M.; Biancotto, G.; Maffini, M.; Scremin, C. L. Nucleic Acids Res. 1993, 21, 1213–1217. doi:10.1093/nar/21.5.1213
Return to citation in text: [1] -
Bonora, G. M.; De Franco, A. M.; Rossin, R.; Veronese, F. M.; Ferruti, P.; Plyasunova, O.; Vorobjev, P. E.; Pyshnyi, D. V.; Komarova, N. I.; Zarytova, V. F. Nucleosides, Nucleotides Nucleic Acids 2000, 19, 1281–1288. doi:10.1080/15257770008033051
Return to citation in text: [1] -
Padiya, K. J.; Salunkhe, M. M. Bioorg. Med. Chem. 2000, 8, 337–342. doi:10.1016/S0968-0896(99)00287-4
Return to citation in text: [1] -
Ballico, M.; Drioli, S.; Morvan, F.; Xodo, L.; Bonora, G. M. Bioconjugate Chem. 2001, 12, 719–725. doi:10.1021/bc010034b
Return to citation in text: [1] -
Lönnberg, H. Beilstein J. Org. Chem. 2017, 13, 1368–1387. doi:10.3762/bjoc.13.134
Return to citation in text: [1]
| 25. | Virnekas, B.; Ge, L.; Plückthun, A.; Schneider, K. C.; Wellnhofer, G.; Moroney, S. E. Nucleic Acids Res. 1994, 22, 5600–5607. doi:10.1093/nar/22.25.5600 |
| 26. | Yáñez, J.; Argüello, M.; Osuna, J.; Soberón, X.; Gaytán, P. Nucleic Acids Res. 2004, 32, e158. doi:10.1093/nar/gnh156 |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 29. | Yagodkin, A.; Azhayev, A.; Roivainen, J.; Antopolsky, M.; Kayushin, A.; Korosteleva, M.; Miroshnikov, A.; Randolph, J.; Mackie, H. Nucleosides, Nucleotides Nucleic Acids 2007, 26, 473–497. doi:10.1080/15257770701426260 |
| 30. | Lyttle, M. H.; Napolitano, E. W.; Calio, B. L.; Kauvar, L. M. BioTechniques 1995, 19, 274–281. |
| 31. | Ono, A.; Matsuda, A.; Zhao, J.; Santi, D. V. Nucleic Acids Res. 1995, 23, 4677–4682. doi:10.1093/nar/23.22.4677 |
| 32. | Kayushin, A. L.; Korosteleva, M. D.; Miroshnikov, A. I.; Kosch, W.; Zubov, D.; Piel, N. Nucleic Acids Res. 1996, 24, 3748–3755. doi:10.1093/nar/24.19.3748 |
| 14. | Gaytán, P.; Yáñez, J.; Sánchez, F.; Soberón, X. Nucleic Acids Res. 2001, 29, E9. doi:10.1093/nar/29.3.e9 |
| 15. | Arkin, A. P.; Youvan, D. C. BioTechnology 1992, 10, 297–300. doi:10.1038/nbt0392-297 |
| 25. | Virnekas, B.; Ge, L.; Plückthun, A.; Schneider, K. C.; Wellnhofer, G.; Moroney, S. E. Nucleic Acids Res. 1994, 22, 5600–5607. doi:10.1093/nar/22.25.5600 |
| 26. | Yáñez, J.; Argüello, M.; Osuna, J.; Soberón, X.; Gaytán, P. Nucleic Acids Res. 2004, 32, e158. doi:10.1093/nar/gnh156 |
| 28. | Zehl, A.; Starke, A.; Cech, D.; Hartsch, T.; Merkl, R.; Fritz, H.-J. Chem. Commun. 1996, 2677–2678. doi:10.1039/cc9960002677 |
| 30. | Lyttle, M. H.; Napolitano, E. W.; Calio, B. L.; Kauvar, L. M. BioTechniques 1995, 19, 274–281. |
| 31. | Ono, A.; Matsuda, A.; Zhao, J.; Santi, D. V. Nucleic Acids Res. 1995, 23, 4677–4682. doi:10.1093/nar/23.22.4677 |
| 33. | Sondek, J.; Shortle, D. Proc. Natl. Acad. Sci. U. S. A. 1992, 89, 3581–3585. doi:10.1073/pnas.89.8.3581 |
| 34. | Adamo, I.; Dueymes, U.; Schönberger, A.; Navarro, A.-E.; Meyer, A.; Lange, M.; Imbach, J.-L.; Link, F.; Morvan, F.; Vasseur, J.-J. Eur. J. Org. Chem. 2006, 436–448. doi:10.1002/ejoc.200500547 |
| 20. | Kayushin, A.; Korosteleva, M.; Miroshnikov, A. Nucleosides, Nucleotides Nucleic Acids 2000, 19, 1967–1976. doi:10.1080/15257770008045471 |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 29. | Yagodkin, A.; Azhayev, A.; Roivainen, J.; Antopolsky, M.; Kayushin, A.; Korosteleva, M.; Miroshnikov, A.; Randolph, J.; Mackie, H. Nucleosides, Nucleotides Nucleic Acids 2007, 26, 473–497. doi:10.1080/15257770701426260 |
| 29. | Yagodkin, A.; Azhayev, A.; Roivainen, J.; Antopolsky, M.; Kayushin, A.; Korosteleva, M.; Miroshnikov, A.; Randolph, J.; Mackie, H. Nucleosides, Nucleotides Nucleic Acids 2007, 26, 473–497. doi:10.1080/15257770701426260 |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 25. | Virnekas, B.; Ge, L.; Plückthun, A.; Schneider, K. C.; Wellnhofer, G.; Moroney, S. E. Nucleic Acids Res. 1994, 22, 5600–5607. doi:10.1093/nar/22.25.5600 |
| 29. | Yagodkin, A.; Azhayev, A.; Roivainen, J.; Antopolsky, M.; Kayushin, A.; Korosteleva, M.; Miroshnikov, A.; Randolph, J.; Mackie, H. Nucleosides, Nucleotides Nucleic Acids 2007, 26, 473–497. doi:10.1080/15257770701426260 |
| 20. | Kayushin, A.; Korosteleva, M.; Miroshnikov, A. Nucleosides, Nucleotides Nucleic Acids 2000, 19, 1967–1976. doi:10.1080/15257770008045471 |
| 35. | Ferreira, F.; Meyer, A.; Vasseur, J.-J.; Morvan, F. J. Org. Chem. 2005, 70, 9198–9206. doi:10.1021/jo051172n |
| 33. | Sondek, J.; Shortle, D. Proc. Natl. Acad. Sci. U. S. A. 1992, 89, 3581–3585. doi:10.1073/pnas.89.8.3581 |
| 45. | Lönnberg, H. Beilstein J. Org. Chem. 2017, 13, 1368–1387. doi:10.3762/bjoc.13.134 |
| 21. | Jabgunde, A. M.; Molina, A. G.; Virta, P.; Lönnberg, H. Beilstein J. Org. Chem. 2015, 11, 1553–1560. doi:10.3762/bjoc.11.171 |
| 22. | Kungurtsev, V.; Lonnberg, H.; Virta, P. RSC Adv. 2016, 6, 105428–105432. doi:10.1039/C6RA22316H |
| 23. | Matsuno, Y.; Shoji, T.; Kim, S.; Chiba, K. Org. Lett. 2016, 18, 800–803. doi:10.1021/acs.orglett.6b00077 |
| 34. | Adamo, I.; Dueymes, U.; Schönberger, A.; Navarro, A.-E.; Meyer, A.; Lange, M.; Imbach, J.-L.; Link, F.; Morvan, F.; Vasseur, J.-J. Eur. J. Org. Chem. 2006, 436–448. doi:10.1002/ejoc.200500547 |
| 39. | Dueymes, C.; Schönberger, A.; Adamo, I.; Navarro, A.-E.; Meyer, A.; Lange, M.; Imbach, J.-L.; Link, F.; Morvan, F.; Vasseur, J.-J. Org. Lett. 2005, 7, 3485–3488. doi:10.1021/ol0511777 |
| 40. | Bonora, G. M.; Scremin, C. L.; Colonna, F. P.; Garbesi, A. Nucleic Acids Res. 1990, 18, 3155–3159. doi:10.1093/nar/18.11.3155 |
| 41. | Bonora, G. M.; Biancotto, G.; Maffini, M.; Scremin, C. L. Nucleic Acids Res. 1993, 21, 1213–1217. doi:10.1093/nar/21.5.1213 |
| 42. | Bonora, G. M.; De Franco, A. M.; Rossin, R.; Veronese, F. M.; Ferruti, P.; Plyasunova, O.; Vorobjev, P. E.; Pyshnyi, D. V.; Komarova, N. I.; Zarytova, V. F. Nucleosides, Nucleotides Nucleic Acids 2000, 19, 1281–1288. doi:10.1080/15257770008033051 |
| 43. | Padiya, K. J.; Salunkhe, M. M. Bioorg. Med. Chem. 2000, 8, 337–342. doi:10.1016/S0968-0896(99)00287-4 |
| 44. | Ballico, M.; Drioli, S.; Morvan, F.; Xodo, L.; Bonora, G. M. Bioconjugate Chem. 2001, 12, 719–725. doi:10.1021/bc010034b |
| 38. | Semenyuk, A.; Földesi, A.; Johansson, T.; Estmer-Nilsson, C.; Blomgren, P.; Brännvall, M.; Kirsebom, L. A.; Kwiatkowski, M. J. Am. Chem. Soc. 2006, 128, 12356–12357. doi:10.1021/ja0636587 |
| 34. | Adamo, I.; Dueymes, U.; Schönberger, A.; Navarro, A.-E.; Meyer, A.; Lange, M.; Imbach, J.-L.; Link, F.; Morvan, F.; Vasseur, J.-J. Eur. J. Org. Chem. 2006, 436–448. doi:10.1002/ejoc.200500547 |
| 39. | Dueymes, C.; Schönberger, A.; Adamo, I.; Navarro, A.-E.; Meyer, A.; Lange, M.; Imbach, J.-L.; Link, F.; Morvan, F.; Vasseur, J.-J. Org. Lett. 2005, 7, 3485–3488. doi:10.1021/ol0511777 |
| 36. | Lietard, J.; Hassler, M. R.; Fakhoury, J.; Damha, M. J. Chem. Commun. 2014, 50, 15063–15066. doi:10.1039/C4CC07153K |
| 37. | Xu, J.; Duffy, C. D.; Chan, C. K. W.; Sutherland, J. D. J. Org. Chem. 2014, 79, 3311–3326. doi:10.1021/jo5002824 |
| 22. | Kungurtsev, V.; Lonnberg, H.; Virta, P. RSC Adv. 2016, 6, 105428–105432. doi:10.1039/C6RA22316H |
| 23. | Matsuno, Y.; Shoji, T.; Kim, S.; Chiba, K. Org. Lett. 2016, 18, 800–803. doi:10.1021/acs.orglett.6b00077 |
| 21. | Jabgunde, A. M.; Molina, A. G.; Virta, P.; Lönnberg, H. Beilstein J. Org. Chem. 2015, 11, 1553–1560. doi:10.3762/bjoc.11.171 |
| 1. | Chen, Z.; Zeng, A.-P. Curr. Opin. Biotechnol. 2016, 42, 198–205. doi:10.1016/j.copbio.2016.07.007 |
| 2. | Bornscheuer, U. T.; Huisman, G. W.; Kazlauskas, R. J.; Lutz, S.; Moore, J. C.; Robins, K. Nature 2012, 485, 185–194. doi:10.1038/nature11117 |
| 3. | Truppo, M. D. ACS Med. Chem. Lett. 2017, 8, 476–480. doi:10.1021/acsmedchemlett.7b00114 |
| 4. | Ernst, P.; Plückthun, A. Biol. Chem. 2017, 398, 23–29. doi:10.1515/hsz-2016-0233 |
| 9. | Derbyshire, K. M.; Salvo, J. J.; Grindley, N. D. Gene 1986, 46, 145–152. doi:10.1016/0378-1119(86)90398-7 |
| 19. | Arunachalam, T. S.; Wichert, C.; Appel, B.; Müller, S. Org. Biomol. Chem. 2012, 10, 4641–4650. doi:10.1039/c2ob25328c |
| 24. | Raetz, R.; Appel, B.; Müller, S. Chim. Oggi 2016, 34, 14–17. |
| 22. | Kungurtsev, V.; Lonnberg, H.; Virta, P. RSC Adv. 2016, 6, 105428–105432. doi:10.1039/C6RA22316H |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 29. | Yagodkin, A.; Azhayev, A.; Roivainen, J.; Antopolsky, M.; Kayushin, A.; Korosteleva, M.; Miroshnikov, A.; Randolph, J.; Mackie, H. Nucleosides, Nucleotides Nucleic Acids 2007, 26, 473–497. doi:10.1080/15257770701426260 |
| 8. | Sauer, N. J.; Mozoruk, J.; Miller, R. B.; Warburg, Z. J.; Walker, K. A.; Beetham, P. R.; Schöpke, C. R.; Gocal, G. F. Plant Biotechnol. J. 2016, 14, 496–502. doi:10.1111/pbi.12496 |
| 25. | Virnekas, B.; Ge, L.; Plückthun, A.; Schneider, K. C.; Wellnhofer, G.; Moroney, S. E. Nucleic Acids Res. 1994, 22, 5600–5607. doi:10.1093/nar/22.25.5600 |
| 6. | Packer, M. S.; Liu, D. R. Nat. Rev. Genet. 2015, 16, 379–394. doi:10.1038/nrg3927 |
| 7. | Sullivan, B.; Walton, A. Z.; Stewart, J. D. Enzyme Microb. Technol. 2013, 53, 70–77. doi:10.1016/j.enzmictec.2013.02.012 |
| 20. | Kayushin, A.; Korosteleva, M.; Miroshnikov, A. Nucleosides, Nucleotides Nucleic Acids 2000, 19, 1967–1976. doi:10.1080/15257770008045471 |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 5. | Porter, J. L.; Rusli, R. A.; Ollis, D. L. ChemBioChem 2016, 17, 197–203. doi:10.1002/cbic.201500280 |
| 21. | Jabgunde, A. M.; Molina, A. G.; Virta, P.; Lönnberg, H. Beilstein J. Org. Chem. 2015, 11, 1553–1560. doi:10.3762/bjoc.11.171 |
| 22. | Kungurtsev, V.; Lonnberg, H.; Virta, P. RSC Adv. 2016, 6, 105428–105432. doi:10.1039/C6RA22316H |
| 23. | Matsuno, Y.; Shoji, T.; Kim, S.; Chiba, K. Org. Lett. 2016, 18, 800–803. doi:10.1021/acs.orglett.6b00077 |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 13. | Dale, S. J.; Belfield, M.; Richardson, T. C. Methods 1991, 3, 145–153. doi:10.1016/S1046-2023(05)80167-7 |
| 14. | Gaytán, P.; Yáñez, J.; Sánchez, F.; Soberón, X. Nucleic Acids Res. 2001, 29, E9. doi:10.1093/nar/29.3.e9 |
| 18. | Popova, B.; Schubert, S.; Bulla, I.; Buchwald, D.; Kramer, W. PLoS One 2015, 10, e0136778. doi:10.1371/journal.pone.0136778 |
| 22. | Kungurtsev, V.; Lonnberg, H.; Virta, P. RSC Adv. 2016, 6, 105428–105432. doi:10.1039/C6RA22316H |
| 29. | Yagodkin, A.; Azhayev, A.; Roivainen, J.; Antopolsky, M.; Kayushin, A.; Korosteleva, M.; Miroshnikov, A.; Randolph, J.; Mackie, H. Nucleosides, Nucleotides Nucleic Acids 2007, 26, 473–497. doi:10.1080/15257770701426260 |
| 9. | Derbyshire, K. M.; Salvo, J. J.; Grindley, N. D. Gene 1986, 46, 145–152. doi:10.1016/0378-1119(86)90398-7 |
| 12. | Cárcamo, E.; Roldán-Salgado, A.; Osuna, J.; Bello-Sanmartin, I.; Yáñez, J. A.; Saab-Rincón, G.; Viadiu, H.; Gaytán, P. ACS Omega 2017, 2, 3183–3191. doi:10.1021/acsomega.7b00508 |
| 19. | Arunachalam, T. S.; Wichert, C.; Appel, B.; Müller, S. Org. Biomol. Chem. 2012, 10, 4641–4650. doi:10.1039/c2ob25328c |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 11. | Stemmer, W. P. Proc. Natl. Acad. Sci. U. S. A. 1994, 91, 10747–10751. doi:10.1073/pnas.91.22.10747 |
| 23. | Matsuno, Y.; Shoji, T.; Kim, S.; Chiba, K. Org. Lett. 2016, 18, 800–803. doi:10.1021/acs.orglett.6b00077 |
| 14. | Gaytán, P.; Yáñez, J.; Sánchez, F.; Soberón, X. Nucleic Acids Res. 2001, 29, E9. doi:10.1093/nar/29.3.e9 |
| 15. | Arkin, A. P.; Youvan, D. C. BioTechnology 1992, 10, 297–300. doi:10.1038/nbt0392-297 |
| 16. | Jensen, L. J.; Andersen, K. V.; Svendsen, A.; Kretzschmar, T. Nucleic Acids Res. 1998, 26, 697–702. doi:10.1093/nar/26.3.697 |
| 17. | Tomandl, D.; Schober, A.; Schwienhorst, A. J. Comput.-Aided Mol. Des. 1997, 11, 29–38. doi:10.1023/A:1008071310472 |
| 19. | Arunachalam, T. S.; Wichert, C.; Appel, B.; Müller, S. Org. Biomol. Chem. 2012, 10, 4641–4650. doi:10.1039/c2ob25328c |
| 22. | Kungurtsev, V.; Lonnberg, H.; Virta, P. RSC Adv. 2016, 6, 105428–105432. doi:10.1039/C6RA22316H |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 29. | Yagodkin, A.; Azhayev, A.; Roivainen, J.; Antopolsky, M.; Kayushin, A.; Korosteleva, M.; Miroshnikov, A.; Randolph, J.; Mackie, H. Nucleosides, Nucleotides Nucleic Acids 2007, 26, 473–497. doi:10.1080/15257770701426260 |
| 28. | Zehl, A.; Starke, A.; Cech, D.; Hartsch, T.; Merkl, R.; Fritz, H.-J. Chem. Commun. 1996, 2677–2678. doi:10.1039/cc9960002677 |
| 29. | Yagodkin, A.; Azhayev, A.; Roivainen, J.; Antopolsky, M.; Kayushin, A.; Korosteleva, M.; Miroshnikov, A.; Randolph, J.; Mackie, H. Nucleosides, Nucleotides Nucleic Acids 2007, 26, 473–497. doi:10.1080/15257770701426260 |
| 26. | Yáñez, J.; Argüello, M.; Osuna, J.; Soberón, X.; Gaytán, P. Nucleic Acids Res. 2004, 32, e158. doi:10.1093/nar/gnh156 |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 25. | Virnekas, B.; Ge, L.; Plückthun, A.; Schneider, K. C.; Wellnhofer, G.; Moroney, S. E. Nucleic Acids Res. 1994, 22, 5600–5607. doi:10.1093/nar/22.25.5600 |
| 26. | Yáñez, J.; Argüello, M.; Osuna, J.; Soberón, X.; Gaytán, P. Nucleic Acids Res. 2004, 32, e158. doi:10.1093/nar/gnh156 |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 30. | Lyttle, M. H.; Napolitano, E. W.; Calio, B. L.; Kauvar, L. M. BioTechniques 1995, 19, 274–281. |
| 26. | Yáñez, J.; Argüello, M.; Osuna, J.; Soberón, X.; Gaytán, P. Nucleic Acids Res. 2004, 32, e158. doi:10.1093/nar/gnh156 |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 28. | Zehl, A.; Starke, A.; Cech, D.; Hartsch, T.; Merkl, R.; Fritz, H.-J. Chem. Commun. 1996, 2677–2678. doi:10.1039/cc9960002677 |
| 29. | Yagodkin, A.; Azhayev, A.; Roivainen, J.; Antopolsky, M.; Kayushin, A.; Korosteleva, M.; Miroshnikov, A.; Randolph, J.; Mackie, H. Nucleosides, Nucleotides Nucleic Acids 2007, 26, 473–497. doi:10.1080/15257770701426260 |
| 31. | Ono, A.; Matsuda, A.; Zhao, J.; Santi, D. V. Nucleic Acids Res. 1995, 23, 4677–4682. doi:10.1093/nar/23.22.4677 |
| 32. | Kayushin, A. L.; Korosteleva, M. D.; Miroshnikov, A. I.; Kosch, W.; Zubov, D.; Piel, N. Nucleic Acids Res. 1996, 24, 3748–3755. doi:10.1093/nar/24.19.3748 |
| 27. | Janczyk, M.; Appel, B.; Springstubbe, D.; Fritz, H.-J.; Müller, S. Org. Biomol. Chem. 2012, 10, 1510–1513. doi:10.1039/c2ob06934b |
| 30. | Lyttle, M. H.; Napolitano, E. W.; Calio, B. L.; Kauvar, L. M. BioTechniques 1995, 19, 274–281. |
| 26. | Yáñez, J.; Argüello, M.; Osuna, J.; Soberón, X.; Gaytán, P. Nucleic Acids Res. 2004, 32, e158. doi:10.1093/nar/gnh156 |
| 25. | Virnekas, B.; Ge, L.; Plückthun, A.; Schneider, K. C.; Wellnhofer, G.; Moroney, S. E. Nucleic Acids Res. 1994, 22, 5600–5607. doi:10.1093/nar/22.25.5600 |
| 26. | Yáñez, J.; Argüello, M.; Osuna, J.; Soberón, X.; Gaytán, P. Nucleic Acids Res. 2004, 32, e158. doi:10.1093/nar/gnh156 |
© 2018 Suchsland et al.; licensee Beilstein-Institut.
This is an Open Access article under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
The license is subject to the Beilstein Journal of Organic Chemistry terms and conditions: (https://www.beilstein-journals.org/bjoc)